W module tym wnioskujemy statystycznie z próby losowej o parametrach populacji generalnej. Rolę decydującą odgrywa przy tym prawidłowy wybór modelu rozkładu. Zgodność modelu z wynikami pomiarów oceniana jest metodami graficznymi, testami statystycznymi i przez współczynniki regresji. Prawidłowy wybór modelu pozwala na realistyczną interpretację wyliczanych wskaźników. qs-STAT wyszukuje automatycznie najlepszy model rozkładu.
Metody graficzne to wykresy pomiarów i średnich (także ruchome), strumień wartości, sieci prawdopodobieństwa rozkładów. Są to rozkład normalny, log-normalny, Weibulla, Rayleigha z klasowaniem i bez klasowania z podaniem lub bez przedziałów ufności, box-plot (wykres skrzynkowy) i plot XY dla rozkładów dwuwymiarowych. Pomiary można też opisywać używając funkcji Pearsona, transformacji Johnsona i rozkładu mieszanego. Wskaźniki statystyczne to mediana, średnie, wariancje, rozstępy, udziały poza granicami, momenty oraz wskaźniki Cg/Cgk do oceny zdolności maszyny i zdolności tymczasowej z podaniem przedziałów ufności.
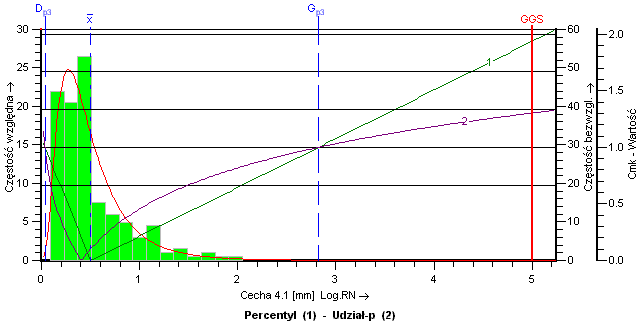
Histogram z nałożonym teoretycznym wykresem rozkładu logarytmiczno-normalnego
Testy statystyczne wykonywane przy szukaniu modelu rozkładu to: Swed-Eisenhart, CHI²-test na dopasowanie, Shapiro-Wilk, D'Agostino, David-Hartly-Pearson, Grubbs oraz Test na trendy, asymetrię i wybrzuszenie.
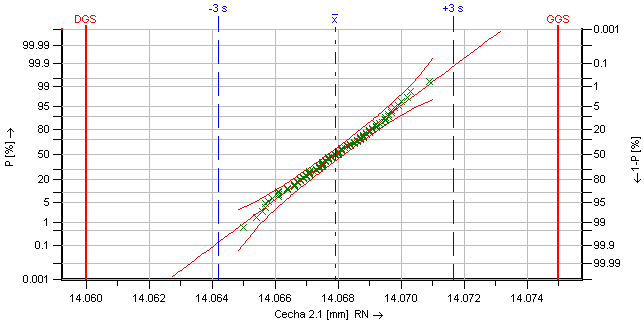
Sieć prawdopodobieństwa
Wyniki pomiarów różnych cech można na wykresie odłożyć na osiach X i Y:
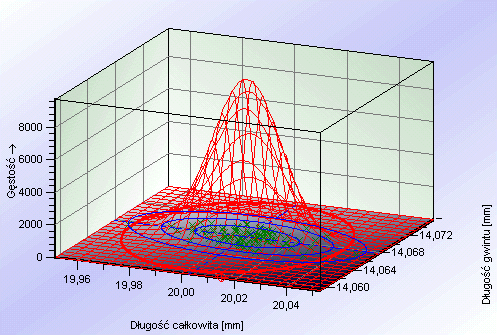
Trójwymiarowy wykres rozkładu dwuwymiarowego, tzw. Plot XY
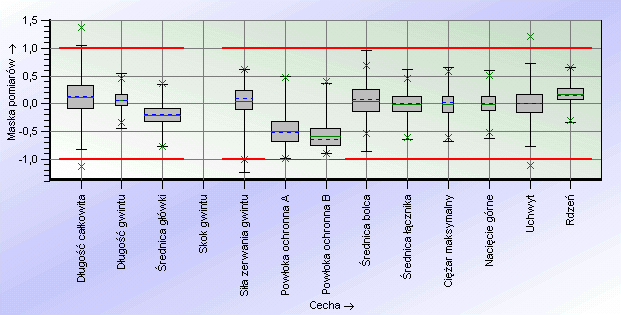
Box-plot: Wykres przeglądowy wielu cech w formie unormowanej
Generatory rozkładów (w menu Dodatki)
Dla porównania, do celów demonstracyjnych lub szkoleniowych można wygenerować dowolny rozkład statystyczny z dowolną liczbą wartości.